- .txt や.csvファイルをseabornで取り扱う.
- 簡単な図示化の方法
- サンプル分布の比較,類似性の検討
こんにちは.けんゆー(@kenyu0501_)です.
今回の記事では,実験データ(.txtや.csv)の分布図をpythonを用いてグラフ化するということをやります.
seabornのライブラリを用いてグラフを作っていきます.
(参考:seabornでグラフを重ねてプロットする方法)
(参考:iris(アヤメ)のデータセットをpandasとseabornを使って可視化する)

これまでも度々扱ってきたけど,図示化に非常に便利なライブラリなんだよ!
グラフを作ることで多くの知見が得られる
このブログでは,分布のあるデータ群(青と赤)に対して,視覚的に構造が理解しやすいようなグラフを作ることを目的としています.
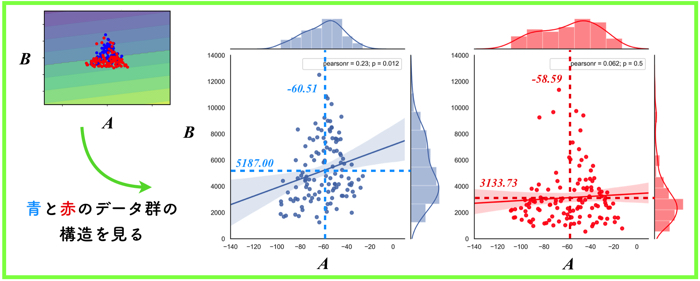
AとBの特徴量を持つ何らかのデータ(背景の色は気にしないで!)を用いていますが,これらグラフは,データがどのように分布しているのかという知見を与えるため,非常に便利です.
データの分布を分かりやすいグラフで表示することによって,例えば以下のことがわかると思います.
- 各データの特徴量は,ほぼ平均値を中心にばらつきがあるように見える.
- 青データでは,2つの特徴量(AとB)に対して弱い相関がある.
- 赤データでは,2つの特徴量に対して無相関になる.
- 特徴量B:青データの方が赤データに比べて広範囲で分布しており,平均値が2000以上も高い.
- 特徴量A:赤データの方が青データに比べて広範囲に分布しているが,平均値はどちらもほぼ同等.
などのように,グラフを作成することができれば,データ分布を言語化して表現することもできます.
こういった知見を与える上で,グラフ作成は非常に便利です.
プログラミングについて
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | #!/usr/bin/env python3 # -*- coding: utf-8 -*- """ Created on Wed Sep 11 23:08:05 2019 @author: ueharakenyuu """ import numpy as np import seaborn as sns from scipy import stats import matplotlib.pyplot as plt #----------解析データの読み込み---------------# inputData_a = "test.txt" dataA = np.loadtxt(inputData_a, delimiter='\t', dtype='float') #-----------------------------------------# X_A_b = dataA[:120, 1:2] X_B_b = dataA[:120, 2:3] X_A_r = dataA[120:240, 1:2] X_B_r = dataA[120:240, 2:3] # 背景を白に設定 #sns.set(style="white", color_codes=True) # それぞれのグラフを出力 sns.jointplot(x=X_A_b, y=X_B_b, kind="reg", color="blue", size=6, xlim=(-140,10), ylim=(0,14000) ).annotate(stats.pearsonr) plt.savefig("test_blue.png", dpi=480) sns.jointplot(x=X_A_r, y=X_B_r, kind="reg", color="red", size=6, xlim=(-140,10), ylim=(0,14000) ).annotate(stats.pearsonr) plt.savefig("test_red.png", dpi=480) |
読み込みデータ
以下のtest.txtというデータを読み込みます.
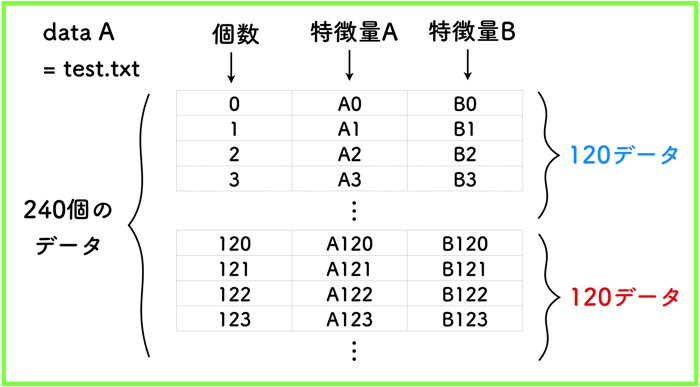
初めの120データは,青データで,残りの120データは赤データになります.
ラベリングを振っても良かったですが,自分でわかると判断できるので特に振ってはいません.
テキストファイルやCSVファイルの読み込みが可能です.
ファイルの中の特定の行や列を取り出したい時は,以下をご覧ください.
(X_A_b = dataA[:120, 1:2]の意味がわかると思います.)
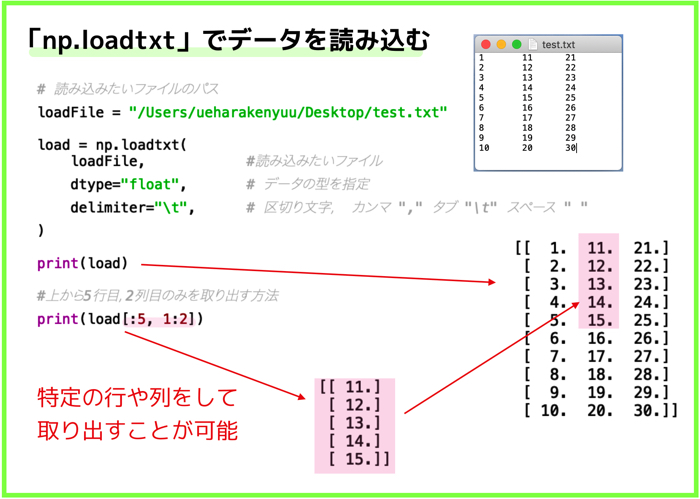
[ : , : ]として,読み込んだ配列の中の特定の行や列を取り出すことができるのですね.
これで,必要な部分の特徴量のみを使って,データの分布を考えることができます.
sns.joinplot()
seabornのjoinplotは非常に便利なツールです.
分布を参照する際にはパパッとデータを広げることができて楽です.
1 2 3 4 5 6 7 8 | sns.jointplot(x=X_A_b, y=X_B_b, kind="reg", color="blue", size=6, xlim=(-140,10), ylim=(0,14000) ).annotate(stats.pearsonr) |
xとyは特徴量ですね.
テキストデータから特定の行と列を抽出しました.
color,size,xlim,ylimはそれぞれ意味が分かると思います.
色と,サイズと,各軸の範囲ですね.
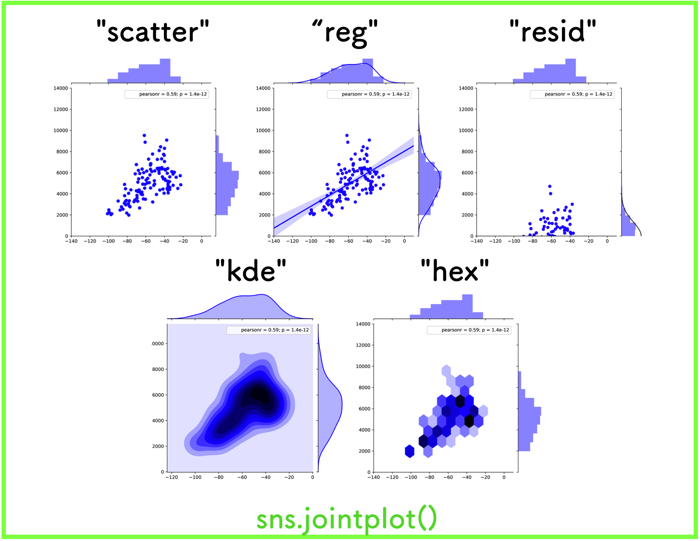
面白いのは,グラフの種類を色々と変更できるkind = ” “というものです.
(先ほどお見せしたグラフは”reg”という種類です.)
kind = ” “の種類
プロットの種類は以下の通りです.
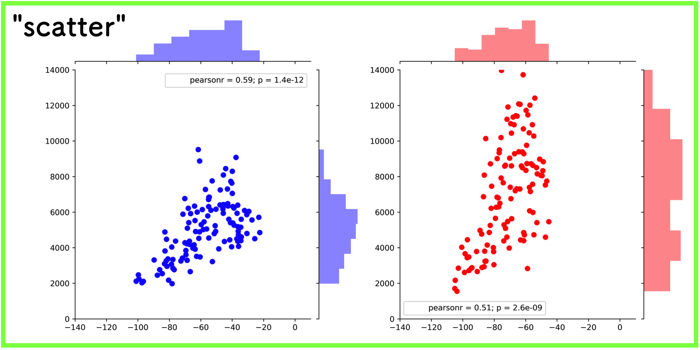
- “scatter”:散布図.
- “reg”:散布図と回帰直線.
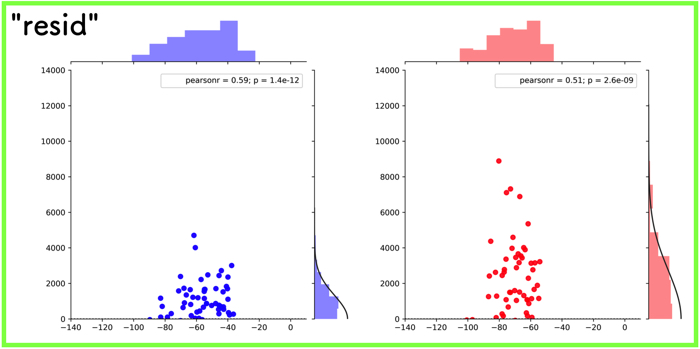
- “resid”:y軸に回帰直線からの誤差を出力する.
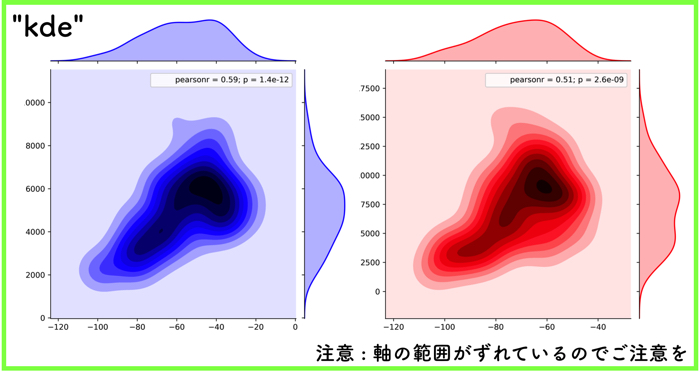
- “kde”:カーネル密度推定を使い等高線でプロットを記述.
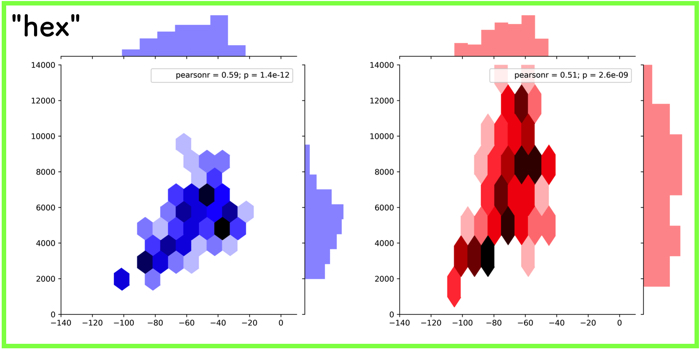
- “hex”:六角形のヒートマップ
それぞれ見ていきます.
“scatter”:散布図
“resid”:y軸に回帰直線からの誤差
“kde”:カーネル密度推定を使い等高線
“hex”:六角形のヒートマップ
自分にとって見やすく比較しやすいようなグラフを上手く活用してください.
平均値などの情報を計算する
.annotate(stats.pearsonr)をつけると,2つの特徴量の相関係数とp値は計算されるのですが,平均値は算出されないです.
(.annotate(stats.pearsonr)は,sis.jointplot()の後ろにつけます.)
平均値や分散などの情報は,別途自分で計算してみて下さい.
1 2 3 4 5 6 | def calculate_mean(data): s = sum(data) N = len(data) return s/N print(calculate_mean(X_A_r)) |
上のプログラムは,平均値の算出なのですがサンプルを足してその数だけなので単純です.
(僕は,平均値を求めて,自分で加工しました...)
みなさんも是非やってみてねー!では!