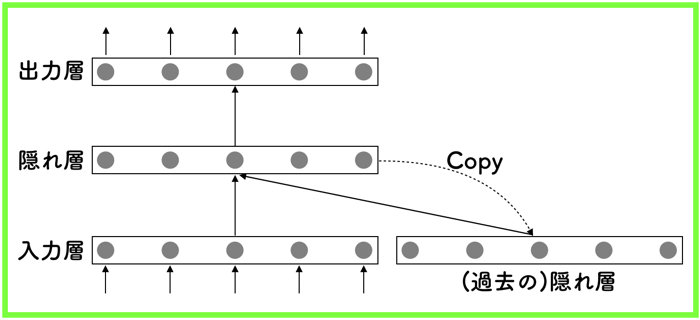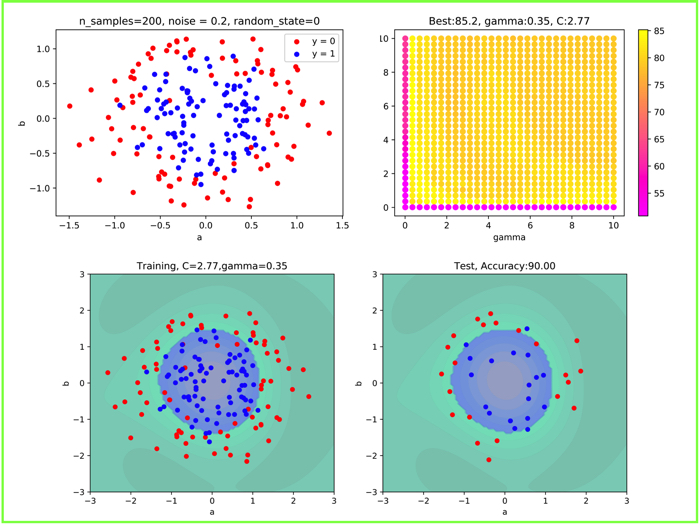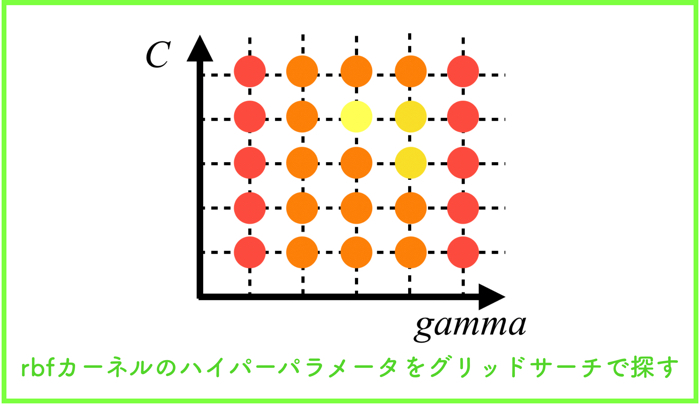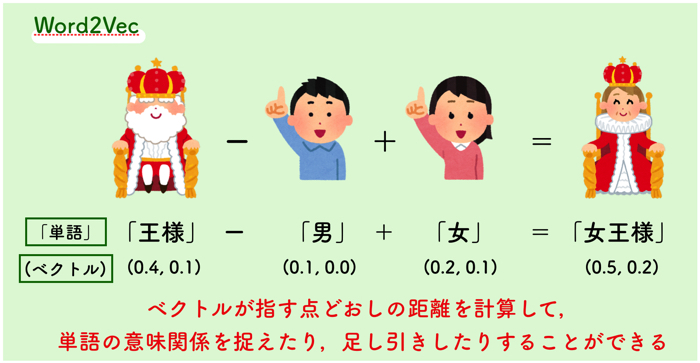
- 機械学習について知りたい人
- G検定の対策をしている人
- 人工知能AIに興味がある人
こんにちは.けんゆー(@kenyu0501_)です.
今日は,話題の人工知能の根源になっている「機械学習」そのものについて取り上げます.
といっても,あまり説明する必要がないくらい,日常に溶け込んできていると思います.
機械学習は,簡単にいうと,「データを反復的に学習して,ある法則を見つけること」です.
または,「自然的に人間が物事を判断できるような仕組みをコンピュータに学習という定義で置き換えたもの」です.

明示的にプログラミングされてなくても,自動的に学習していろんな機能を満足して提供できるようなものなんだね!
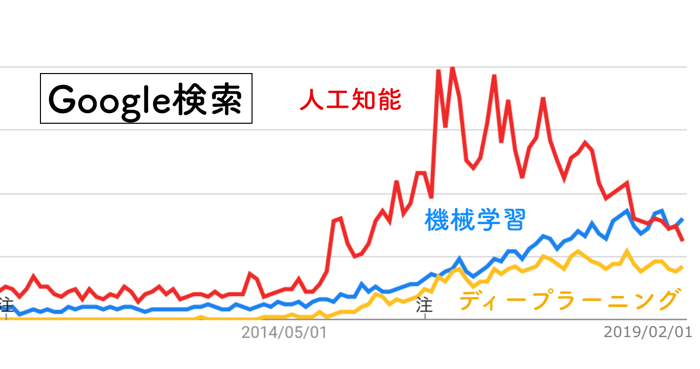
ものすごく期待値が高かった「人工知能」ですが,最近の傾向だと「機械学習」に関する関心が徐々に高まってきていると感じます.
Google 検索数の比較を貼っておきます.
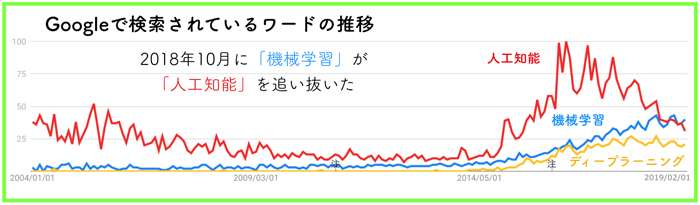
つまり,世の中の関心は,ざっくりとした「人工知能」への過度な期待から,「機械学習」を着実に理解して使っていけるようにしよう,ということが見受けられます.
また,ディープラーニングもついでに表示しましたが,やっぱり「機械学習」の方が関心度は高いようです.
(どちらも似ているようですが,ちょっと違います)
今回は,機械学習について考えていきます.
はじめに:機械学習の身の回りの適用例について
機械学習は,データマイニングや何かしらの予測(モデルの構築)にものすごく力を発揮します.
どちらも,データからパターンを探し,それに応じて内側の動作をちょっとずつ調整していきます.
データさえあれば,人間の介入や支援なしに,コンピュータが自動的に学習し,それに応じて動作を調節できるんだね!
そのため,パターンを探すためには,たくさんのデータが必要になるわけですが,現在のところ,データが集まる場所ではかなり強力なツールとなっています.
以下は,日常に溶け込んだ機械学習のユースケースの一例です.
- インターネット検索でのパーソナライズされた広告
- スパムメールフィルタリング
- ネットワークセキュリティの脅威検索
- 機械やデバイスの予測保守
などなど,その他多岐にわたります.
内側のアルゴリズム:教師あり・教師なし・半教師・強化学習
機械学習のアルゴリズムは,「教師あり」か「教師なし」に大別されますが,「半教師あり」や「強化学習」なんてものもあるので紹介しておきます.
「教師あり」のアルゴリズムの場合の特徴は以下です.
- ラベル(正解)が付いているデータを使用して,ある法則を見つけ,将来の予測を行う.
- 既知のデータセットの分析をし,出力値について予測するための関数を作る.
- 予測器(関数)を作るために使用する変数や機能を決定する.
- 学習後,新しいデータに適用する.
また,「教師なし」のアルゴリズムは以下です.
- ラベルなしのデータから隠れた構造を記述する関数を作る.
- 入力データを反復的に見直して,データタイプの結論を出す.
- 多くの変数間の微妙な相関関係を識別する.
- その結果,新しいデータがどのタイプなのかを解釈することができる
- システムは正しい出力を把握しないが,データセットから推論を引き出すことができる.
基本的に,教師なし学習は,教師ありに比べて,複雑な処理タスクに使用されます.
大量のビックデータが必要になるため,最近,ようやく実現可能になってきた技術です,
また,「半教師あり学習」というのもあります.
- 効率的に学習をしていくための方法の1つ.
- ラベル付きデータとラベルなしデータの両方を学習に使用する.
- 通常は,少量のラベル付きデータと,大量のラベル無しデータが用いられる.
- 適切なラベル付きデータを使用するので,学習時間が大幅に低減される.
- 残りの大量のラベルが付いていないデータは,勝手に学習していく.
最後に強化学習についても記載しておきます.
- ある環境内での行動の誤りや報酬によって,取るべき動作を学習していく方法である.
- エージェント(行動者)のどの動作が最良であるかを学ぶために,報酬のフィードバックが必要である.
- つまり,一連の行動を通じて,報酬が最も多くなるような動作をする.
機械学習の種類:用途や代表的な手法
機械学習とは,収集したデータを学習させてある法則を見つけることでしたが,様々なことに応用できます.
用途に関しては,ほぼ無限にありますが,手法に関しては結構決まっていたりします.
かなり単純なものから,複雑なものまで様々です.
また,用途に応じて機械学習の手法がそれぞれ違うので,先ずはそこをおさらいしていきましょう!
| 用途 | 手法 | 教師 |
|---|---|---|
| 回帰 | 線形回帰,ベイズ回帰 | あり |
| 分類 | サポートベクターマシン,決定木,ニューラルネットワーク,ロジスティック回帰 | あり |
| クラスタリング | K-means法,混合正規分布モデル | なし |
| 情報圧縮 | 主成分分析,特異値分解 | なし |
用途も様々ですが,それに応じた解析手法も様々で,以上のような感じに分けられます.
回帰
過去のデータ(数値)から,未来の数値を予測する時に使われます.
大体は,相関関係を識別して,将来のデータポイントに関する予測を行ったりします.
単回帰分析などは,統計学なんかでも使用されますが,売り上げの予測とか,価格の予測とかそういったものに使われます.最小二乗法なんかが使われたりしますね.
分類
クラス分類とも言いますが,データを適切なクラスに分けることです.
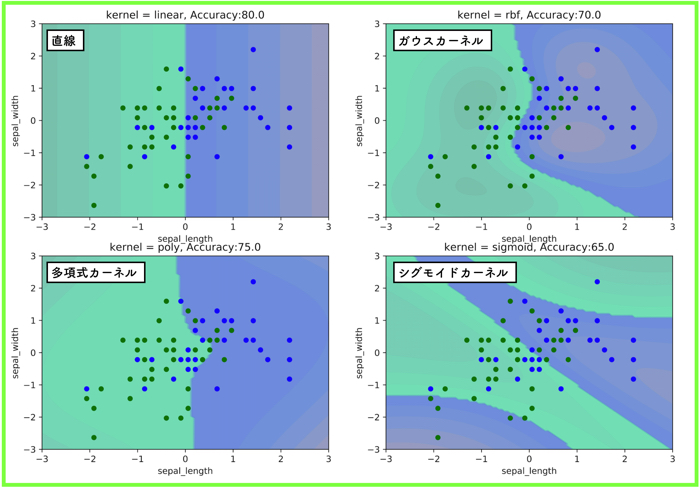
サポートベクターマシンはこの分類問題では非常に有名です.
この記事はこんな人にオススメです サポートベクターマシンSVMについて詳しく知りたい方 機械学習で分類や回帰な…

pythonでプログラム実装まで行なっているのでご覧ください.
決定木のモデルは,ある特定の行動に関する観察を行って,望ましい結果になるような最適な道筋を調べるために使われたりします.
クラスタリング
教師なし学習の分類ですね.
データの類似性を考慮して自動的にグルーピングします.
k-means法が有名です.
具体的には,指定されたグルーピング数へ,同じ特性かどうかを判断してグループ化します.
情報圧縮
取得したデータの次元が大きい場合があるので,そういった場合に次元を下げたりします.
なるべく元データの特徴や傾向などを残しながら,データ量を減らします.
主成分分析が有名ですね!
最後に:参考になるページ
機械学習を直感的に理解したいときは,やっぱり視覚的に動いているものが見たいと思います.
そんな人には,こちらのページが良いです.
英語のページですが,どのようなものがあるかを見ることができるので非常にオススメです.
では!