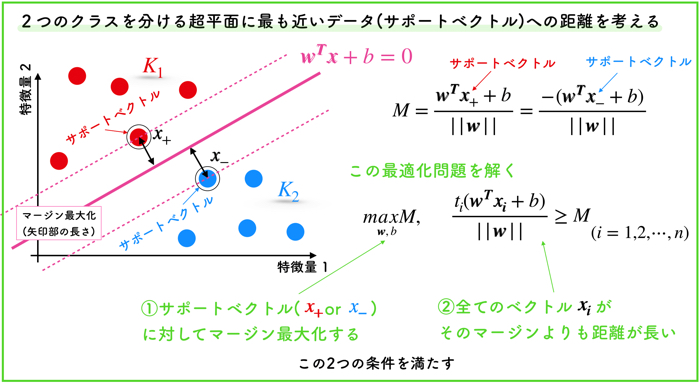
- 自然言語処理の技術についてざっくりと知りたい人
- 人工知能について興味・関心がある人
- G検定の対策をしている人
こんにちは.けんゆー(@kenyu0501_)です.
今日は,自然言語処理についての記事を書きます.
この自然言語処理もかなり面白い技術だと思います.
おいら達人間がコミュニケーションをするときの言葉(例えば日本語とか)は非構造のデータですよね.

おっす,おっ!?今日,顔色いいじゃん!みたいな
もちろんそれは0か1かの世界ではないです.
つまり,コンピュータのような構造化された通信ではないのですね.
人間が話す非構造な言語を機械的にどうのように処理していくか,というものは興味深い研究分野だと思います.
実は,この自然言語処理に関する研究は50年以上前から行われています
自然言語処理とは!?
自然言語処理(NLP)は,人間の言葉を理解し処理することを目指した技術です.
コンピュータは行間を読むことができないですが,それを如何にして(人工知能を用いて)機械的に実装するかが現代の大きな研究テーマだと思います.
未だ人間のようにストレスフリーでペラペラ会話できるロボットは世の中に出てはいませんが,以下のような技術は,ディープラーニングによって実用レベルまでは来ていると思います.
- 言語の自動翻訳
- 言語の理解
(SNSの投稿や商品のレビューなどの分析) - テキストの要約
NLPの大まかな流れ
自然言語処理の大まかな流れは以下のようなものです.
- 形態素解析:文章を最小単位の単語に分け品詞を判定する
- データクレンジング:不要な文字列を取り除く
- BoW (Bag-of-Woeds):ベクトル形式に変換する
- TF-IDF:各単語の重要度を評価する
この順番,G検定でよく問われるから覚えておいたほうが良いぞ!
NLPの解析技術の代表的な種類について
NLPの解析技術に代表的なものを取り上げてまとめておきます.
形態素解析
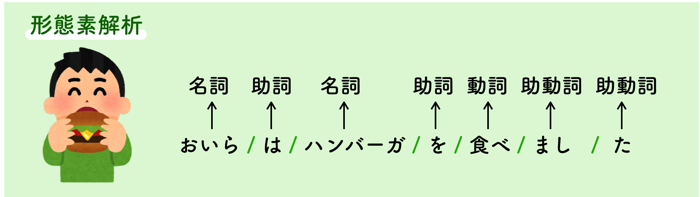
大体はテキストデータの文章(自然言語)から,これ以上分解できないかつ言語で意味を持つ最小単位(形態素)に分割することです.
そして,その形態素の品詞を判定することです.
英語の場合は,単語間にスペースがあり明確だけど,日本語は難しいよね
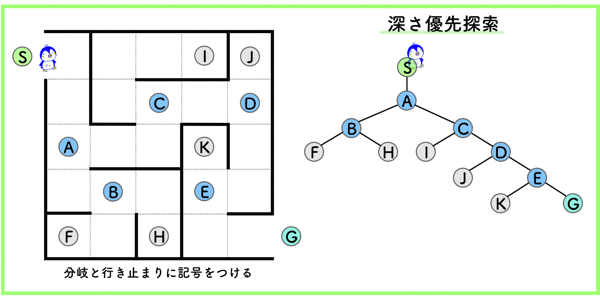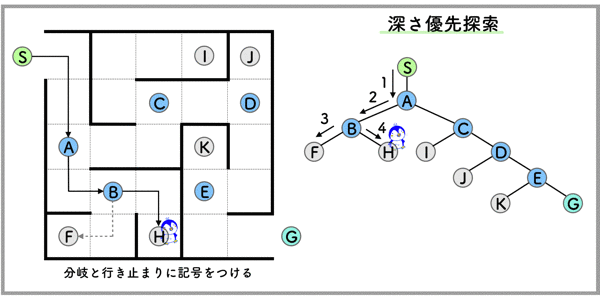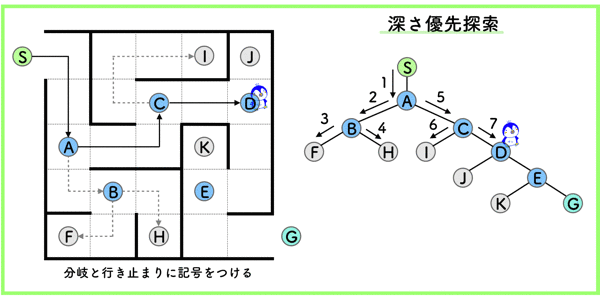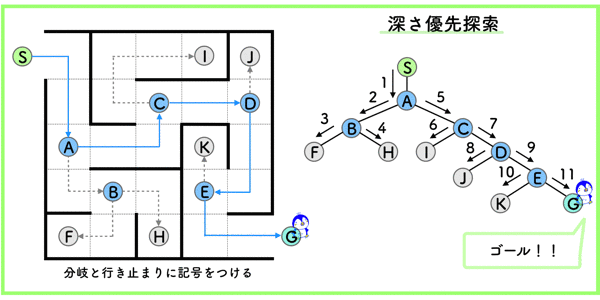
構文解析 (係り受け解析)
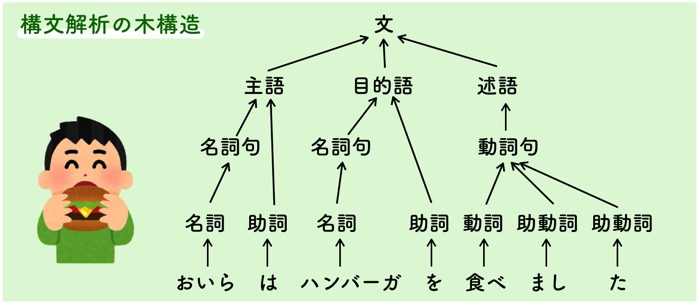
形態素間の構造的関係を解析することです.
つまり,上の絵のような木構造にして,構造的関係をはっきりさせることです.
含意関係解析
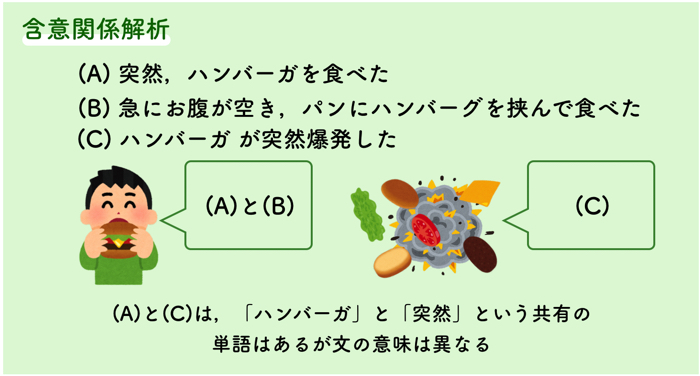
2つの文の間に,含意関係が成立するかを判別することです.
上の3つの文章だと,(A)と(B)は,含意関係が一致してますが,(C)は一緒ではありません.
(A)と(C)は同じ「ハンバーガ」と「突然」という単語が入っていますが,意味は異なります.
このように同じ単語が使われていても,必ずしも文の出来事は同じであるということは限らないです.
含意関係解析では,違う表現で書かれていても,同じ意味(出来事や概念)はまとめ,そうでないものは,区別できるというところが重要です.
意味解析
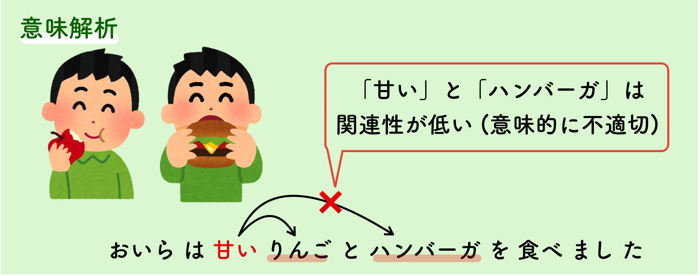
意味を持つまとまりを判定することです.
つまり,単語間の関連性を調べて適切な構文木を選択することです.
文脈解析

複数の文の構造や意味を考えるというとても複雑な解析のことです.
文の繋がりを確認する解析を行うので,これまでの文単位での構文解析よりもとても高度なものになります.
しかし,これまでの解析の延長にある一番高度な処理なので,一般的にコンピュータが自然言語処理を完了するプロセスだと以下のようになります.
- 形態素解析
- 構文解析
- 意味解析
- 文脈解析
の順番です.
文脈解析が一番高次の層です.
また,以下に続く,照応解析や談話解析も文脈解析の一部です.
照応解析(しょうおうかいせき)

照応詞(代名詞や指示詞など)の指示対象・省略された名詞を推定・補完することです.
日本語はよく主語が省略されるので,多言語へ翻訳するときに補完したりする場合に使います.
談話解析
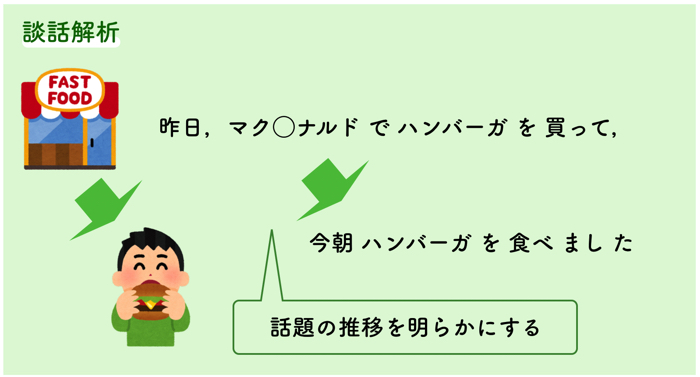
文章中の文と文の役割関係や,話題の推移を明らかにすることです.
話の流れがつかめるようになります.
LDA (Latent Dirichlet Allocation)
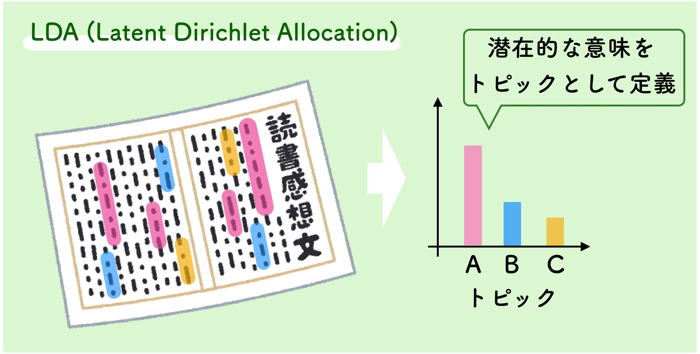
教師なし学習の1つで,文中の単語から,何のトピックかを推定する方法です.
各単語が「隠れたあるトピック」から生成されるものとし,そのトピックを推定するものです.
LSI (Latent Semantic Indexing)
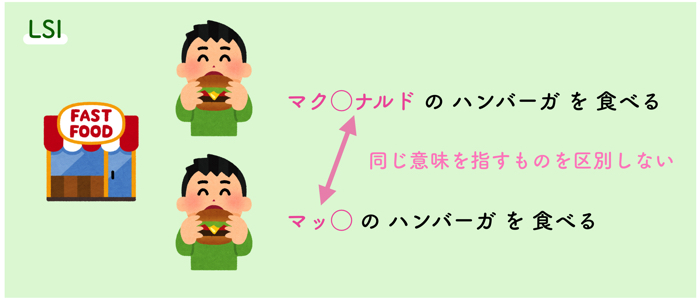
LSIは,次元圧縮手法です.
文章ベクトルにおいて,複数の文章に共通に現れる単語を解析することにより,低次元の潜在意味空間を構成する方法です.
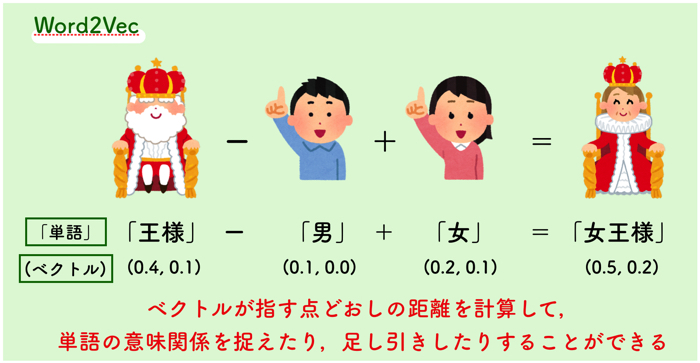
Googleが作ったWord2Vec(ワードツーベック)とは!?
2013年にGoogleによって開発されたWord2Vecは,単語の意味関係を捉えるための計算を行うための仕組みです.
文章中の単語は,単なる文字列として扱う事ができるので,その文字列をベクトルとして表現することにより,演算を可能にし,その結果単語の特徴を表現するという方法です.
Word2Vecは,ベクトル空間モデルとか,単語埋め込みモデルとかって言われたりするぞ!
ちょっと内側のアルゴリズムの話をすると,Word2Vecは,テキストを処理するための2層のニューラルネットです.
入力がテキストデータ(文字列)で,出力が一連の特徴ベクトルです.
Word2Vecはディープニューラルネットワークではないですが,テキストをコンピュータが理解できる数値形式に変換することです.
これによって,構文解析が可能になります.
Word2Vecの目的は,類似した単語を数学的に検出して,単語の特徴をベクトル空間にまとめて処理することです.
十分なデータ(用法や文脈)が与えられると,単語の意味について非常に正確な推測が可能です.
これらの推測を利用して,単語と単語の結び付けが可能です.
(例えば,「男性=男の子」など)
Word2Vecは各単語をベクトルにエンコードするため,オートエンコーダとちょっと似ていますが,他の単語に対してトレーニングするという点で異なります.
Word2vecの2つの手法:CBOWとSkip-gram
Word2Vecには,CBOWとSkip-gramという2つの手法があります.
どちらのモデルも中間層が入力層の意味表現表します.

CBOW (Countinuous Bag-of-Words )
CBOWの特徴は以下です.
- 単語周辺の文脈から中心の単語を推定する.
- 非線形な隠れ層がない.
- Projection層で,入力層全てのデータを共有した.
Skip-gramモデル
Skip-gramモデル
- 中心の単語からその文脈を構成する単語を推定する.
- 単語と文脈をランダムに選択することで,正例と負例を分類する学習器を作る.
- その時に,入力データの特徴を低次元化した隠れ層のベクトルを取り出す.
最後に
こんな感じでこんなで終わります!
G検定を受験する方頑張ってくださいね!
この記事を読んでくれた人にオススメです.
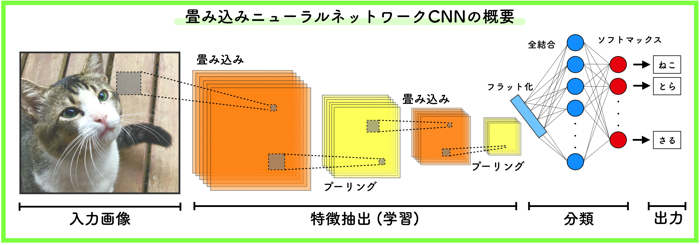
この記事はこんな人にオススメです. 人工知能について興味がある人 畳み込みニューラルネットワークについてざっく…