- PythonのSeabornライブラリでグラフを作っている方
- 比較するデータの表示方法を探している方
- 大学生や研究生の方でグラフの作り方を覚えたい方
こんにちは.けんゆー(@kenyu0501_)です.
今日は,PythonのSeabornライブラリでグラフを作成するときに,「二つ以上のグラフを一枚の図の中に貼り付けて比較する方法」を紹介します.
Seabornは,Pythonの可視化ツールの一つで,matplotlibをベースにしたライブラリです.
これを使えるようになると,おそらく他のグラフ作成ツールはほとんど必要なくなると思います.
大学生や,データを扱っている方でグラフをよく作成するという人にはオススメです.
例題を使ってデータを比較する
やっていることを分かり易くするため,以下のような例題を扱って,それをグラフ化していきます.
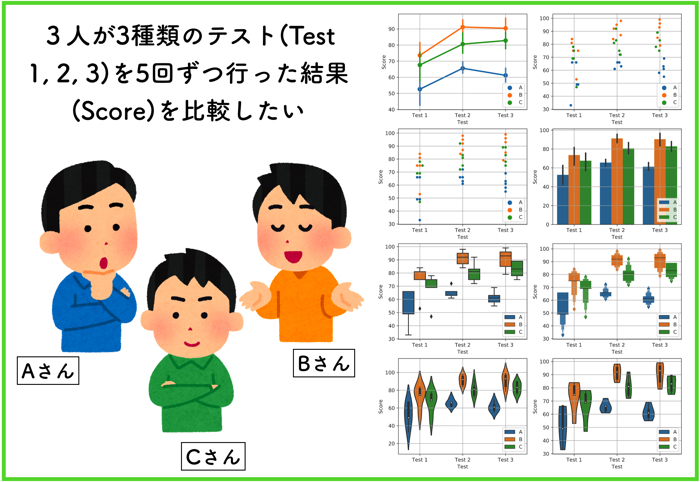
例題:Aさん,Bさん,Cさんが3種類のテストを5回ずつ行った結果を同じグラフの上で比較するグラフをSeabornを使って比較していきます.
Seabornのインストール
PythonのSeabornライブラリを扱うために,インストールをしておいてください.
インストールは,Anacondaとpipを用いる二つの方法があります.
Anaconda環境
1 | conda install seaborn |
pipを使う方法
1 | pip install Seaborn |
自分が使っているPythonの環境に応じて,どちらかのコマンドでseabornをインストールしておいてください!
基本的にプログラミングですが覚えてしまうと簡単です.
グラフを用いてScoreを比較する
先にグラフを表示しておきます.
今回は8つのグラフを紹介します.
(が,分布の結果を比較するのに不向きなものもあります)
①pointplot (点プロット)
②stripplot (直線プロット)
③swarmplot(群れプロット)
④barplot(棒グラフ)
⑤boxplot(箱ひげプロット)
⑥lvplot(要約値プロット)
⑦violinplot (ヴァイオリンプロット)
⑧violinplot (ヴァイオリンプロット(歪みなし))
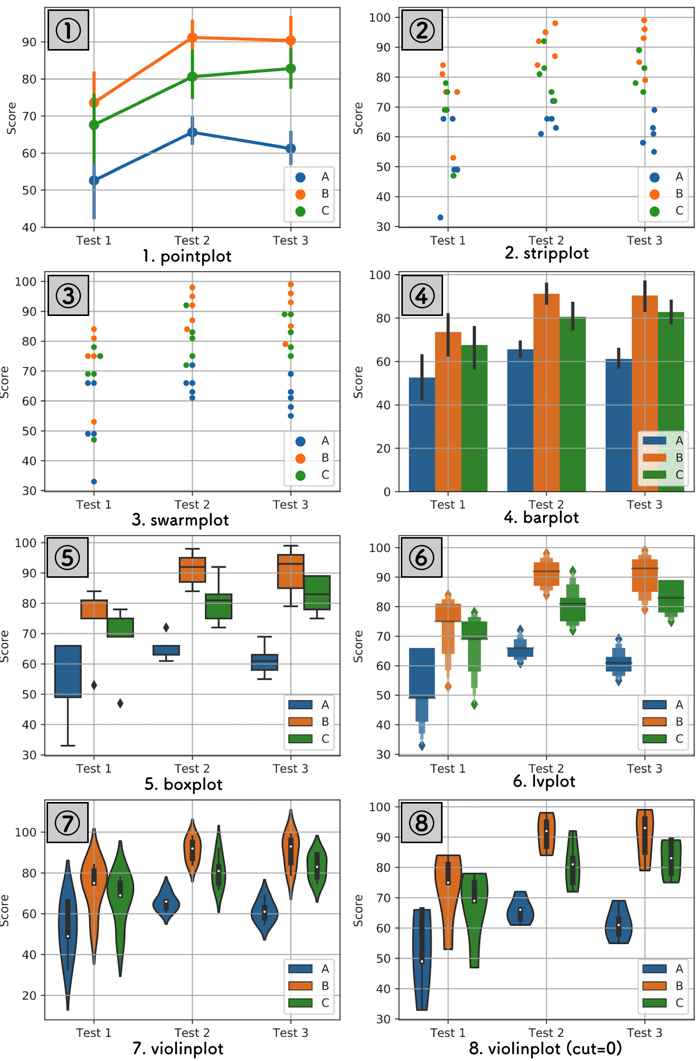
これらのデータはすべて,同じデータを使用しています.
データをグラフにするときの表示方法を変えているだけです.
それぞれのデータは,csvファイルで以下のように格納しています.
ファイルの内側のデータに関して
csvじゃなくても良いですが,とりあえず,このようなデータとして保存されています.
1列目はテストの種類(Test1,Test2,Test3)
2列目は人(Aさん,Bさん,Cさん)
3列目はそれぞれのスコアです.
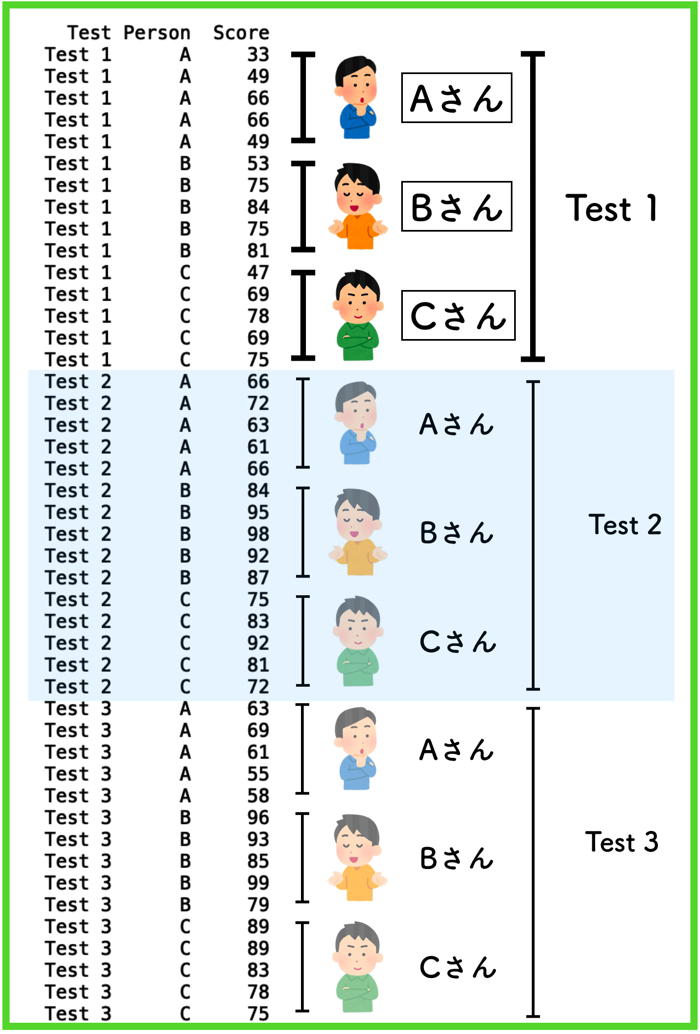
csvファイルも貼っておきますね.
(よかったら使ってください)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | Test,Person,Score Test 1,A,33 Test 1,A,49 Test 1,A,66 Test 1,A,66 Test 1,A,49 Test 1,B,53 Test 1,B,75 Test 1,B,84 Test 1,B,75 Test 1,B,81 Test 1,C,47 Test 1,C,69 Test 1,C,78 Test 1,C,69 Test 1,C,75 Test 2,A,66 Test 2,A,72 Test 2,A,63 Test 2,A,61 Test 2,A,66 Test 2,B,84 Test 2,B,95 Test 2,B,98 Test 2,B,92 Test 2,B,87 Test 2,C,75 Test 2,C,83 Test 2,C,92 Test 2,C,81 Test 2,C,72 Test 3,A,63 Test 3,A,69 Test 3,A,61 Test 3,A,55 Test 3,A,58 Test 3,B,96 Test 3,B,93 Test 3,B,85 Test 3,B,99 Test 3,B,79 Test 3,C,89 Test 3,C,89 Test 3,C,83 Test 3,C,78 Test 3,C,75 |
樹形図的に保存されていますが,データがあまり多くない場合はこのような形態でも良いと思います.
Pythonのプログラミング
上の4×2の8つのグラフを作成したプログラムを記載しておきます.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | # -*- coding: utf-8 -*- """ Created on Mon Apr 29 20:49:23 2019 @author: ueharakenyuu """ import pandas as pd import matplotlib.pyplot as plt import seaborn as sns CSV = pd.read_csv('seaborn_blog.csv') plt.figure(figsize=(10, 16)) #1 plt.subplot(421) ax = sns.pointplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"]) ax.legend(loc='lower right') ax.grid() #2 plt.subplot(422) ax = sns.stripplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"]) ax.legend(loc='lower right') ax.grid() #3 plt.subplot(423) ax = sns.swarmplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"]) ax.legend(loc='lower right') ax.grid() #4 plt.subplot(424) ax = sns.barplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"]) ax.legend(loc='lower right') ax.grid() #5 plt.subplot(425) ax = sns.boxplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"]) ax.legend(loc='lower right') ax.grid() #6 plt.subplot(426) ax = sns.lvplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"]) ax.legend(loc='lower right') ax.grid() #7 plt.subplot(427) ax = sns.violinplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"]) ax.legend(loc='lower right') ax.grid() #8 plt.subplot(428) ax = sns.violinplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"],cut=0) ax.legend(loc='lower right') ax.grid() #plt.show() plt.savefig('seaborn_brog.png',dpi=1200) |
csvファイルをpandasを使って読み込んで,seabornでグラフを書いています.
基本的には,グラフを描写する関数が変わっただけです.
自分のデータの量や種類と相談して,どのグラフを使うか決めてくださいね!
では各プロットの詳細を確認していきましょう.
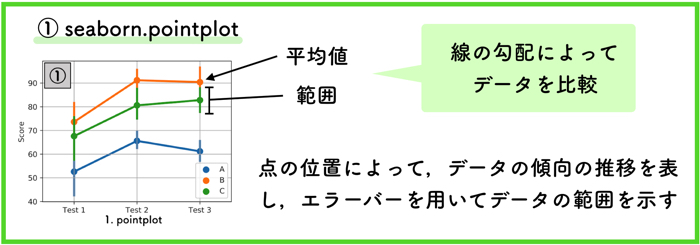
① pointplot
1 | ax = sns.pointplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"]) |
seaborn.pointplotの詳しいページはこちら(英語)です.
ポイントプロットは,点の位置で示した平均値と,縦棒で示したデータの範囲によってグラフ化されています.
データの表示がシンプルなので,直感的に分かりやすく,よく使われます.
大事な値はデータの平均値の推移なので,そこを重点的に見たい場合は,pointplotを使うことをお勧めします.
② stripplot

1 | ax = sns.stripplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"]) |
seaborn.stripplotの詳しいページはこちら(英語)です.
こちらは散布図ですね.
stripplotはデータの点を全てプロットし,生データがどのように分布しているのか単純に表示したい場合に役に立ちます.
今回のように3人のデータを比較するといった場合は不向きかも知れないですが,ある単独な課題を複数回実行した時の分布データや,ある単独の条件での観測結果の表示には役に立つと思います.
さらに後に出てくる⑤boxplotや⑦violinplotなどと組み合わせて使用すると,効果的な場合もあります.
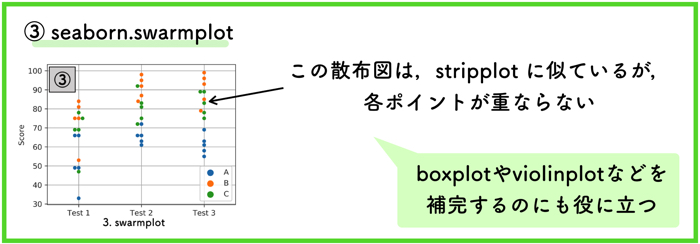
③ swamplot
1 | ax = sns.swarmplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"]) |
seaborn.swarmplotの詳しいページはこちら(英語)です.
こちらのプロット方法は,②stripplotに非常によく似てますが,各点が重ならないのが特徴です.
重ならないため,綺麗な描画ができますが,データが多数存在する場合は,表示が上手くスケールされない場合があります.
そういった場合は,デフォルトから軸範囲を拡張するなどといった設定が必要になります.
こちらも,後に出てくる⑤boxplotや⑦violinplotなどと組み合わせて使用すると,効果的な場合があります.
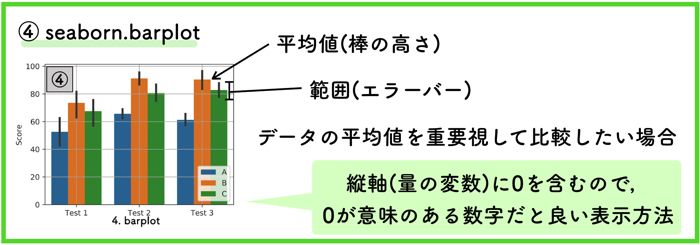
④barplot
1 | ax = sns.barplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"]) |
seaborn.barplotの詳しいページはこちら(英語)です.
こちらは棒グラフですね.
エクセルなどにも標準で入っているので,多くの人が使ったことがあるのではないでしょうか.
各棒グラフの高さは,代表値としてデータの平均を示しています.
またエラーバーはデータの範囲を示しています.エラーバーをみると大体のばらつきが分かります.
大体は,縦軸に0を含むため,縦軸の0が意味のある数字だとより効果的な表示方法になります.
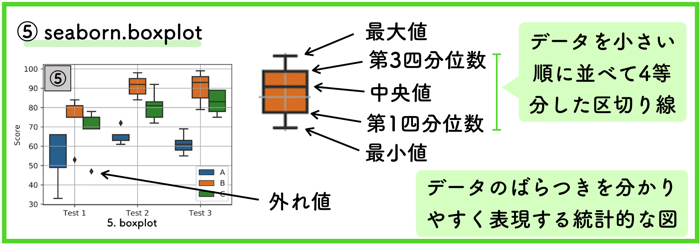
⑤ boxplot
1 | ax = sns.boxplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"]) |
seaborn.boxplotの詳しいページはこちら(英語)です.
こちらは箱ひげ図を表します.
データ分析者が好んで使用する統計的な表示方法です.
分布の情報量がコンパクトにまとまった図なので,この箱ひげ図を見るだけでデータがおおよそどのように散っているのかすぐに確認することが可能です.
この図の書き方は,データを小さい順に並べて,4等分にした区切りを表示しているだけです.
もっとも小さいデータ(最小値)から,もっとも大きいデータ(最大値)の範囲で表示されますが,明らかにおかしい異常値と判断されるもの(使用者が決める)を外れ値とします.
⑥ lvplot
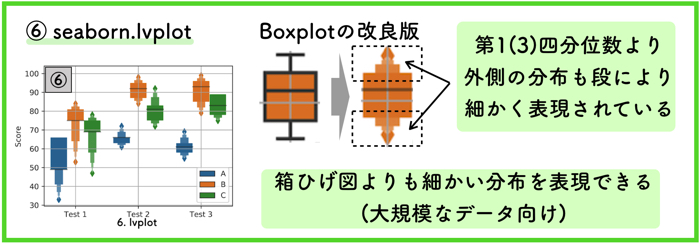
1 | ax = sns.lvplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"]) |
『letter value plot (lvplot)』はこれまでの箱ひげ図よりもさらに詳細な表示を実現した図です.
2011年に提唱された大規模なデータ用の箱ひげ図です.
従来の箱ひげ図は,四分位数を超えるヒゲで書かれる末端部(最小値〜第1四分位数,第3四分位数〜最大値)の振る舞いについては詳細な図ではありませんでした.ただの棒でした.
これがlvplotになると,参照値(letter value)を利用して,詳細な情報を末端にかけて伝達し段で表現します.
詳しくは,20ページほどの論文が公開されているのでそちらをご覧ください.
(Letter-value plots: Boxplots for large data (pdfです))
⑦ ⑧ violinplot
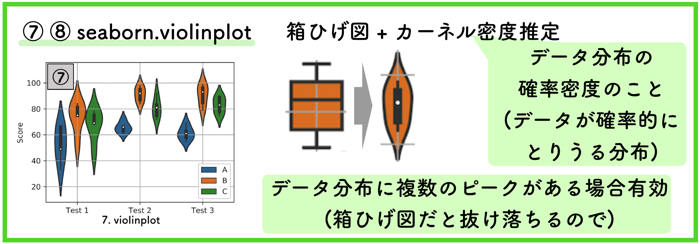
1 | ax = sns.violinplot(x=CSV["Test"], y =CSV["Score"], hue=CSV["Person"]) |
seaborn.violinplotの詳しいページはこちら(英語)です.
バイオリン図は,箱ひげ図にデータ分布のカーネル密度推定をプロットしたものです.
カーネル密度推定とは,確率密度関数を推定する方法の一つです.
これによって,データ集団の分布を確率的に連続な線として表現することができます.
これによって,名前のごとくバイオリンのような形状になります.
これは,データの多くの情報が一つの図に集約されているので,非常に魅力的な表示です.
特に,分布の中に複数のピークがある場合,誤解を与えない有効的な図です.
しかし知名度が低いマイナーな図なので,初見の人には見辛い図なのが難点です.
ちょっとした問題点
実は⑧の図もバイオリンプロットなのですが,これは,ある理由があって末端の表示を無効にしてます.
cutパラメータで「0」を指定したら,図の末端を切り捨てることができます.
実はバイオリンプロットは,カーネル密度推定で曲線を描くとき,分布によって図が歪んでデータの範囲以上の部分を表示してしまうのですよね.
今回のデータだとscoreは100点以上は出ないはずですが,確率密度を計算したら100を超える可能性が計算されてます.そういうのは現実的に起こり得ないので,cut=0で切り捨てた図が⑧になっています.
関連記事
以下はオススメです.