- irisのデータセットを具体的に知りたい人
- seabornとpandasを使って展開したい人
こんにちは.けんゆー(@kenyu0501_)です.
サポートベクターマシンなどの機械学習を試してみたいと思ったときには,Scikit-learnのデータセットを使ってみるのは楽で良い方法だと思います.
その中でも,提供されているアヤメのデータ(iris)は,よく使われるデータセットです.
今回は,そのアヤメのデータセットがどのような構造になっているのかや,実際にseabornやpandasを用いてグラフ化してみようと思います.
アヤメのデータセットとは!?
アヤメ(iris)は,もしかしたら機械学習を扱う世界中のデータサイエンティストに最も知られた花の品種かもしれないですね.
なぜなら,1936年に「The use of multiple measurements in taxonomic problems (分類問題における複数箇所の測定の使用) 」(実際の論文PDFはこちら)で3種類のアヤメが使用されて以来,機械学習などの分野で広く扱われてきたからです.
Ronald Fisherさんという方が執筆されましたが,この論文は現在2000回以上も引用されており,irisのデータは,機械学習を学ぶ上で登竜門的なSVMなどに使用される有名なデータセットです.
- 3種類の花 (Setosa, Virginia, Versicolor )
- 4つの特徴量 (がく片と花びらの幅と長さ)
- 150サンプル(50サンプルずつ)
3種類のアヤメ(Setosa, Virginica, Versicolor )
実際にScikit-Learnで提供されているアヤメ(iris)は以下の3種類です.

画像データはClassification of Iris Varietiesから引用させていただきました.
3種類のアヤメですが,それぞれ4つの特徴量を持っています.
3種類のアヤメは,以下です.
- Setosa (ヒオウギアヤメ)
- Virginica
- Versicolor
setosaは日本でも取れるようなので和名がありましたが,残りの二つは和名はありませんでした.
(2015年の北海道医療大学学術レポジトリの植物の学名,英名および和名で検索しました➡︎「PDFはこちら」)
ただ,アヤメは世界でも150種以上存在しているので,かなり多いです.Scikit-Learnのデータセットはその中の3種類なのですね.
4つの特徴量
4つの特徴量は,sepal(がく片)とpetal(花びら)の長さと幅ですね.cmで数値が入っています.
これら4つの特徴が,種間で異なると報告されて以来,よく機械学習のデータセットとして用いられています.
150のサンプル(1種類は50サンプルずつ)
これらのデータが全部で150サンプル提供されています.
1種類は50サンプルずつです.では,実際にどのようなものが入っているのか確認していきましょう.
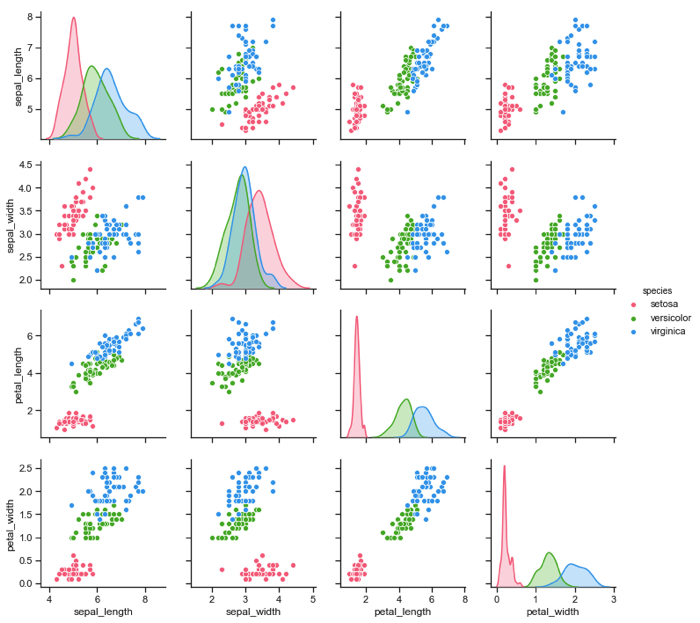
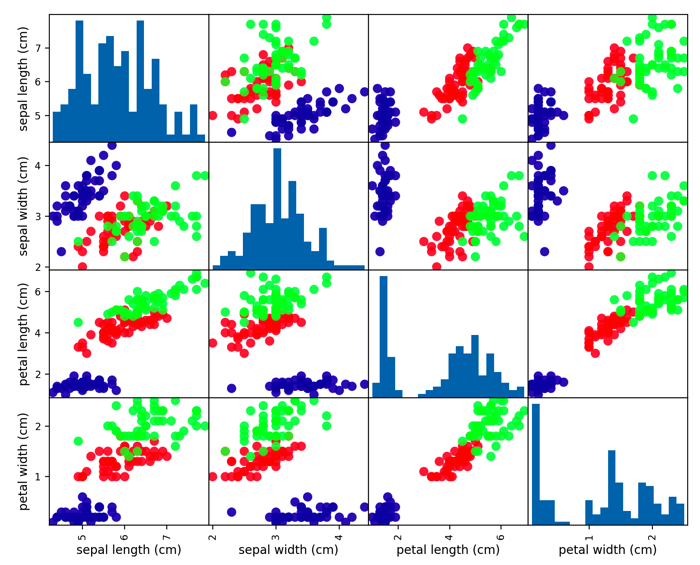
(この図は,pythonのseabornで作りました.また後ほどプログラムについて解説します.)
縦軸と横軸には4つの特徴量の,がく片の長さ,がく片の幅,花びらの長さ,花びらの幅の分布をプロットしてます.
赤がSetosa,緑がVersicolor,青がVirginicaです.
それぞれの大きさの特徴量から,種別間の違いが見れます.
- 花びらの長さと幅は,Virginica > Versicolor > Setosa の順である.
- がく片の幅に関しては,Setosa が最も大きくて,VirginicaとVersicolorがほぼ同じくらいである.
- がく片の長さは,Virginica > Versicolor > Setosa である.
- VirginicaとVersicolorはほとんど似ているが,若干,Virginicaが大きい.
- Setosaを見分けることは,他の二つに比べて簡単そうである.
こういった種別間の違いが提供されているデータから観察することができます.
提供されているデータの構造を見る
実際に,Pythonを用いて提供されているデータ構造にアクセスしてみます.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | from sklearn.datasets import load_iris iris_dataset = load_iris() ############データの確認として################### print("Keys of iris_dataset: \n{}" .format(iris_dataset.keys())) print("First five columns of data: {}" .format(iris_dataset['data'][:5])) print("Shape of data: {}" .format(iris_dataset['data'].shape)) print(iris_dataset['DESCR'][:193] + "\n...") print("Feature names: {}" .format(iris_dataset['feature_names'])) print("First five columns of target: {}" .format(iris_dataset['target'][:5])) print("Filename: {}" .format(iris_dataset['filename'])) print("Target names: {}" .format(iris_dataset['target_names'])) |
以上のプログラムを回すと,とりあえず,どのようなデータが入っているのか確認することができます.
具体的に説明していくと以下のようになります.
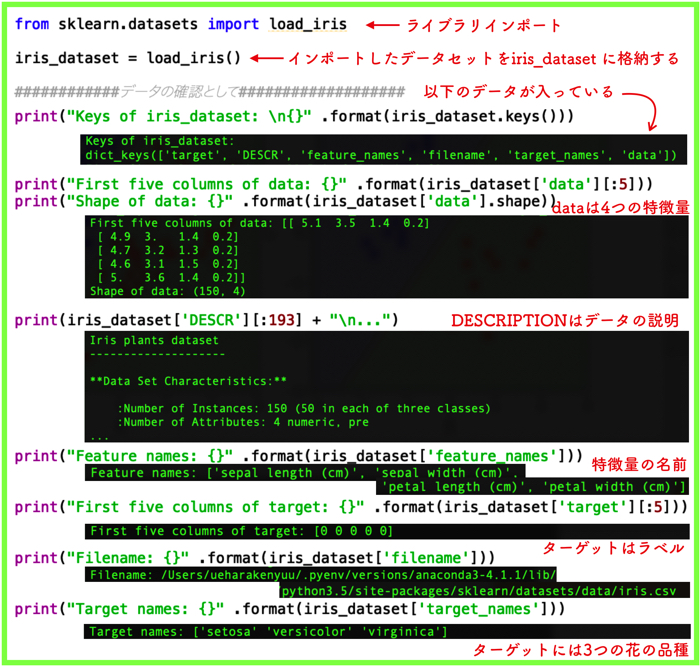
load_irisが返すデータは,キーと値を持ちます.
キーDESCRは,データセットの簡単な説明(description)を表します.
dataの配列には,花の特徴量の測定結果が格納されています.
それぞれじっくり確認してみてください.
pandasを使って図示する
pandasを使って図示するプログラムを掲載しておきます.
pandasをしようすると以下のような分布図が書けます.
プログラムに関して
プログラムは以下です.細かい設定は各自で行なってください.
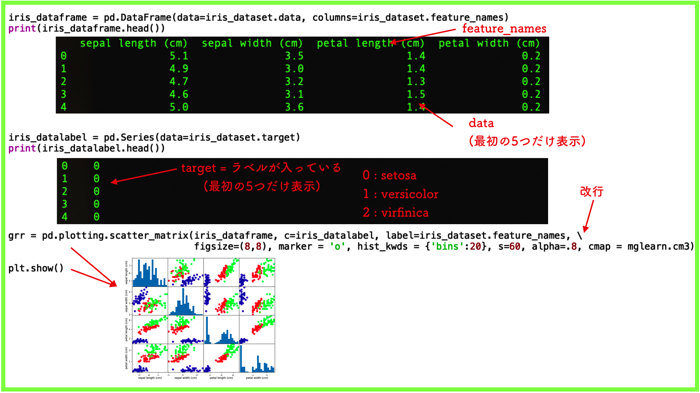
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import pandas as pd import mglearn from sklearn.datasets import load_iris iris_dataset = load_iris() ############pandasを使った図示################### iris_dataframe = pd.DataFrame(data=iris_dataset.data, columns=iris_dataset.feature_names) print(iris_dataframe.head()) iris_datalabel = pd.Series(data=iris_dataset.target) print(iris_datalabel.head()) gr = pd.plotting.scatter_matrix(iris_dataframe, c=iris_datalabel, figsize=(8,8), marker = 'o', hist_kwds = {'bins':20}, s=60, alpha=.8, cmap = mglearn.cm3) plt.show() |
pd.plotting.scatter_matrix( )の関数で図を書いていますが,内側の引数で色々と設定が可能です.詳しくはこちらの公式ドキュメント(こちら英語)をご覧ください
ざっくりと分かる範囲で解説をしてきます.
- c=iris_datalabel
散布図(matplotlibのscatter)に渡る引数で,iris_datalabel(3種類)に応じた配色. - figsize=(8,8)
図の全体のサイズ - marker = ‘o’
散布図に渡る引数でマーカーの形を指定.他にも’+’や’^’がある. - hist_kwds = {‘bins’:20}
ヒストグラムの棒の数. - s=60
マーカーのサイズ. - alpha=.8
透明度を指定. - cmap = mglearn.cm3
matplotlibのカラーマップを指定.
ぜひ使ってみてくださいね!
Seabornで図示する
今度はpandasではなく,seabornを使って図示します.
おいらはどちらかというと,このseabornを使って図示する方が多いです.
1 2 3 4 5 6 | from sklearn.datasets import load_iris import seaborn as sns ############seabornを使った図示################### iris_dataset = sns.load_dataset("iris") sns.pairplot(iris_dataset, hue='species', palette="husl").savefig('seaborn_iris.png') |
こっちはライブラリインポートの定義を含めて4行で書けます.
sns.load_dataset("iris")を使って,irisデータセットをpandasのDataFrameとして読み込んでいます.
その後,pairplot()でグラフをつくります.
.pngの拡張子で保存するところまでやっときましょう.
seabornのpairplotの詳細は,公式ページに詳しく書かれています.
また,seabornに関しては,以下の記事もオススメです.
(参考:【jointplot】実験データ(.txtや.csv)の分布図をpythonで図示化し比較する)
以下はオススメです.
「Pythonではじめる機械学習」