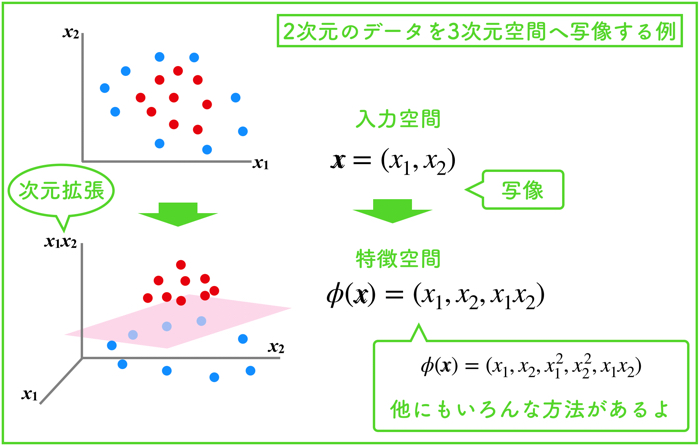
- RBFカーネルを使ったSVMによる非線形分離を実施.
- make_circleのnoiseの異なるデータで検証.
- グリッドサーチと交差検証(クロスバリデーション)も扱う.
こんにちは.けんゆー(@kenyu0501_)です.
https://twitter.com/kenyu0501_/status/1167323135542063105
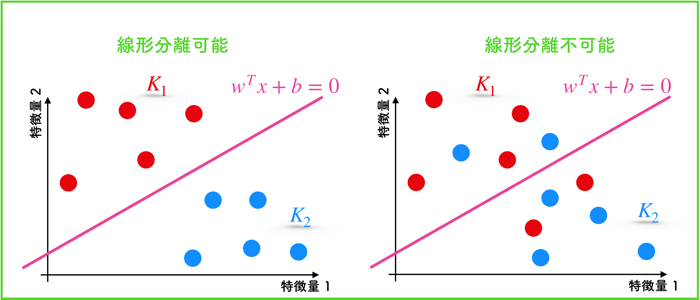
やっぱりRBFカーネルでSVMを試すときには,こういった線形分離不可能なデータの方が見栄えが良いですよね.
闇雲にやってて分かりにくい対象を使っていましたが,反省しています.
この記事では,線形分離不可能なデータを使ってSVMでクラス分類を解きます.
使用するデータは,Scikit-learnのmake_circlesのデータです.
(参考:Scikit-learnのデータセットについて【make_blobs, make_moons, make_circles】)
クラスの異なるデータ群が,円状に配置されているデータですね.
外側と内側に分布しているので,直線での分離ができないわけです.
この記事では,rbfカーネルを使用します.
さらに,グリッドサーチ,クロスバリデーションも行なって,ハイパーパラメータ(γとC)のチューニングも実施します.
プログラムについて
先に,pythonによるプログラムを公開しておきます.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 | """ Created on Sun Aug 25 14:36:27 2019 @author: ueharakenyuu """ import numpy as np import matplotlib.pyplot as plt import pandas as pd from sklearn.datasets import make_circles from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.svm import SVC from sklearn.model_selection import cross_val_score #------データの読み込みと使うデータの選択-----------# X, y = make_circles(n_samples=200, shuffle = True, noise = 0.1, random_state=0, factor = 0.5) a0, b0 = X[y==0,0], X[y==0,1] a1, b1 = X[y==1,0], X[y==1,1] plt.figure(figsize=(8, 7)) fig, ax = plt.subplots() plt.scatter(a0, b0, marker='o', c="red", s=25, label="y = 0") plt.scatter(a1, b1, marker='o', c="blue", s=25, label="y = 1") plt.legend() plt.xlabel("a") plt.ylabel("b") #plt.show() plt.title("n_samples=200, noise = 0.1, random_state=0") fig.savefig('output_circle.png',dpi=900) #------データの読み込みと使うデータの選択-----------# scaler = StandardScaler() X = scaler.fit_transform(X) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2,random_state = 0) X_train_val, X_val, y_train_val, y_val = train_test_split(X_train, y_train, test_size = 0.2,random_state = 0) #------グリッドサーチとクロスバリデーションを使ったハイパーパラメータチューニング-----------# best_score = float(0.0) gammas = np.linspace(0.01, 10, 30) Cs = np.linspace(0.01, 10, 30) best_param_gamma = 0.0 best_param_C = 0.0 scores = pd.DataFrame() for gamma in gammas: for C in Cs: svm = SVC(kernel = 'rbf', gamma=gamma, C=C) scores = scores.append( { 'gamma': gamma, 'C': C, 'accuracy': np.mean(cross_val_score(svm, X_train_val, y_train_val, cv=5)) }, ignore_index=True) if best_score < np.mean(cross_val_score(svm, X_train_val, y_train_val, cv=5)): best_score = np.mean(cross_val_score(svm, X_train_val, y_train_val, cv=5)) best_param_gamma = gamma best_param_C = C print("ベストスコア:", round(best_score,2)) print('g:%s c:%s' %(round(best_param_gamma,2),round(best_param_C,2))) fig, ax = plt.subplots() ax.set_xlabel('gamma') ax.set_ylabel('C') ax = ax.scatter(scores.gamma, scores.C, c=100.0*scores.accuracy, cmap='spring') fig.colorbar(ax) plt.title('Best:{}, gamma:{}, C:{}'.format(100*round(best_score,3), round(best_param_gamma,2),round(best_param_C,2))) fig.savefig('output_gs.png',dpi=900) #------グリッドサーチとクロスバリデーションを使ったハイパーパラメータチューニング-----------# #------グリッドサーチで求めた最適なパラメータでSVMを回す-----------# gamma = best_param_gamma C = best_param_C svm = SVC(kernel = 'rbf', gamma=gamma, C=C) svm.fit(X_train, y_train) R = svm.predict(X_test) total = len(X_test) success = sum(R == y_test) print("Accuracy is:{}".format(100*success/total)) #------グリッドサーチで求めた最適なパラメータでSVMを回す-----------# #----------グラフ描写用の関数---------------# def plot_decision_function(model): _x0 = np.linspace(-3.0, 3.0, 100) _x1 = np.linspace(-3.0, 3.0, 100) x0, x1 = np.meshgrid(_x0, _x1) X = np.c_[x0.ravel(), x1.ravel()] y_pred = model.predict(X).reshape(x0.shape) y_decision = model.decision_function(X).reshape(x0.shape) plt.contourf(x0, x1, y_pred, cmap='winter_r', alpha=0.4) plt.contourf(x0, x1, y_decision,levels=10, alpha=0.2) def plot_dataset(X,y): plt.plot(X[:, 0][y==0], X[:, 1][y==0], "ro", ms=5) plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bo", ms=5) plt.xlabel("a") plt.ylabel("b") #---------------------------------------# #--グラフを描写するor保存する(1行2列で)------# plt.figure(figsize=(12,5)) plt.subplot(121) plot_decision_function(svm) plot_dataset(X_train,y_train) plt.title('Training, C={:.2f},gamma={:.2f}'.format(C,gamma)) plt.subplot(122) plot_decision_function(svm) plot_dataset(X_test,y_test) plt.title('Test, Accuracy:{:.2f}'.format(100.0*success/total)) plt.savefig('svm_output.png',dpi=900) #plt.show() #--------------------------------------# |
データの切り分け
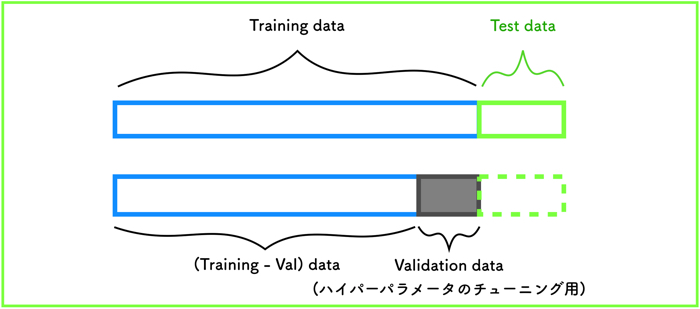
SVMを実施するときには,トレーニングデータ(80%)とテストデータ(20%)に分けます.
今回は,パラメータのチューニングも行うので,トレーニングデータからさらに20%をバリデーション(評価)データとして分けます.
データ全体の構図(データセットから解析まで)

扱うデータを,先ほど示したような感じでデータを切り分け,トレーニングデータとバリデーションデータを使って,ハイパーパラメータのチューニングを行います.
ハイパーパラメータのチューニングは,グリッドサーチとクロスバリデーションです.
(関連:rbfカーネルのハイパーパラメータをグリッドサーチとベイズ最適化で探す【irisデータセット】)
make_circlesのnoiseを色々と変えてSVMの実装
make_circleのデータセットにノイズを適当に入れて,SVMの結果がどのようになるのかを可視化しようと思います.
noise = 0.1

noiseの混入が少ないので,円状のデータセットはまだ形状を保っていますね.
この時のSVMの結果を見ると,かなり汎化性能が高いです.
グリッドサーチに関しても,どこのパラメータをとっても結果が良いことがわかります.
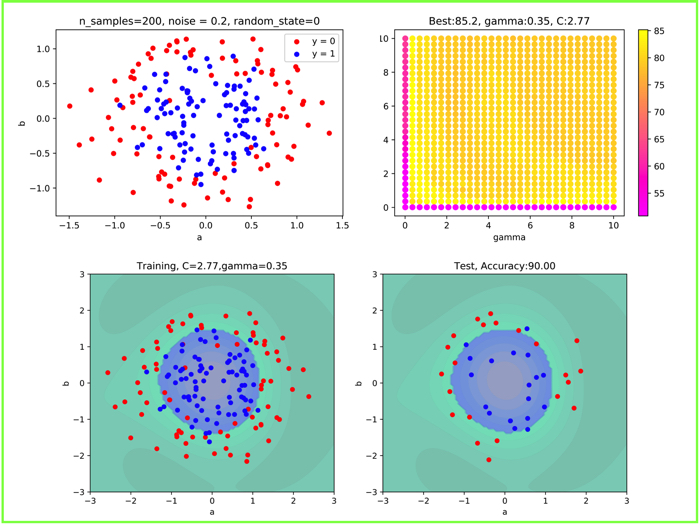
noise = 0.2
noise = 0.2にすると,内側の青いデータ群と,外側の赤いデータ群がちょっと入り組んだような形になります.
この時は,汎化性能が90%になりました.
それでもそこそこ機能しています.
noise = 0.3
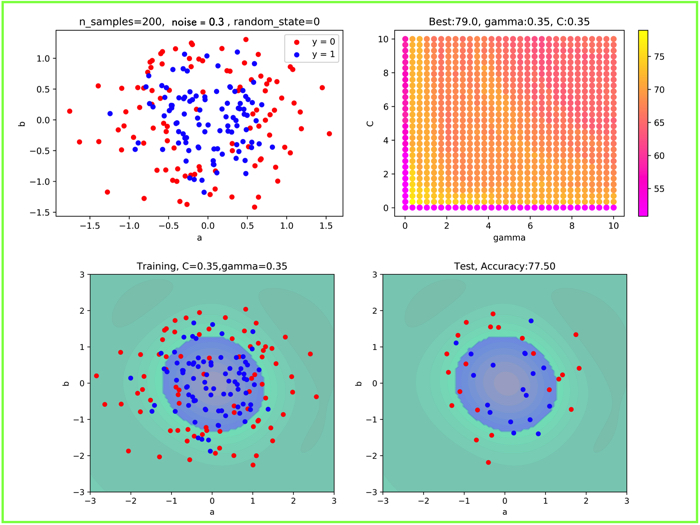
noise = 0.3 になると,かなり複雑ですね.
グリッドサーチの結果も,全体的に,かなり汎化性能が低くなっていることがわかります.
一番良い箇所で,77.5%でした.

興味のある人はやってみてねー!
サポートベクターマシンの解説動画
参考にしてみてくださいー!