- 2019年センター試験の数学1Aを受けた人
- データ分析の数量の変換について詳しく知りたい人
- 標準化という概念をしっかり理解したい人
こんにちは.
2019年1月19日と20日はセンター試験がありましたね.
受験された皆様お疲れ様でした.
さて,今回記事で取り上げるのは,統計学でよく見られる「標準化(もしくは正規化,基準化)」というものです.
数学1Aの第2問「データの分析」の後半部分に,数量の変換というところででてきましたね!

これを知っていた人は,簡単に解けたんじゃないかな!?
標準化というものを,知っているだけですぐに得点がもらえるラッキー問題でした.
知らなくても答えを考えることができますが,センター試験は時間が大事なので,こういうところで節約していきたいですよね!
では早速見ていきましょう!
標準化とは!?
標準化とは,以下のような操作のことです.
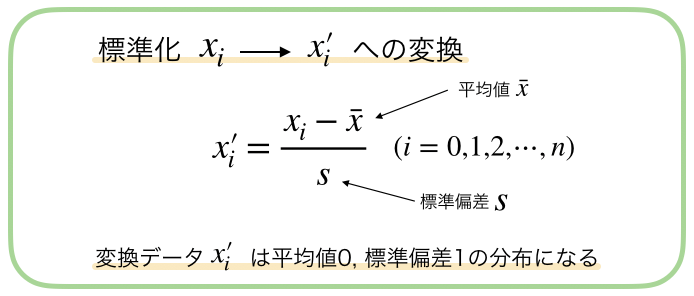
データの値を比較しやすい値に変換するものです.
全てのデータxに対して,平均値で引き,さらに標準偏差で割る,という変換をしています.
標準偏差で割ることによって,値の単位が無次元化されるので,他のデータを比較するときに,データ全体にある大きさという概念が無くなります.
標準化されたデータは,平均値が0,標準偏差が1になります.
どういう意図があって,このような操作をしているかというと,
大きさが異なるデータを比較するためです.
ここでいう大きさとは,データの平均値とか単位とかそういうものです.
割ったり引いたりして,比較できるような形にしてますね.
以下が,センター試験,数学1Aの第2問の問題です.
センター試験の問題から

センター試験でも「標準化」でましたね.
異なるデータの大きさを比較できるようにするために,平均値を引いて,標準偏差で割るということをしてます.
センター試験ではこの後に,「モンシロチョウの所見日」と「ツバメの所見日」の二つのデータの比較を行うための定義の確認でしょうか.
標準化をした新たなデータは,「平均値が0」になり,「標準偏差が1」になるのは,上で説明した通りですが,センターの問題は速攻で解決できます.
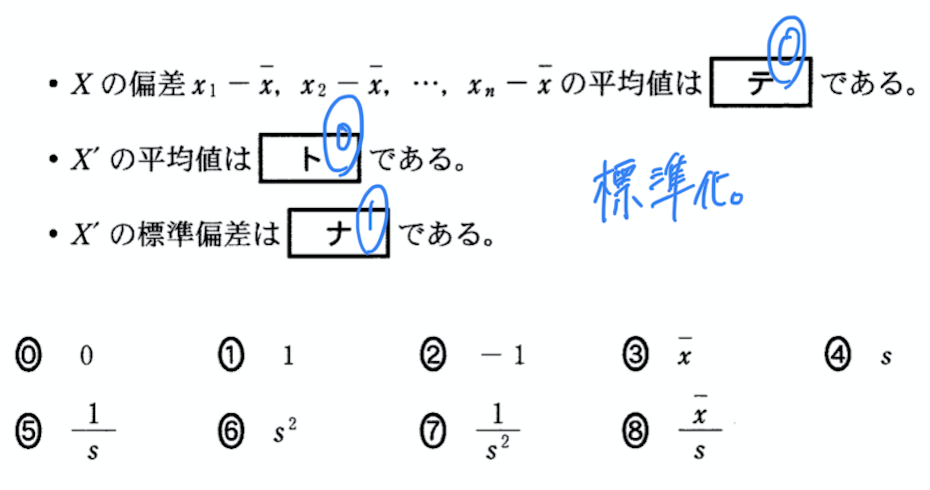
これは,全てのデータから平均値を引いて,バラツキ分布の標準偏差で割っているため,熟考すると,答えがわかったかもしれません.
しかし,標準化の与式を見たときに,平均値と標準偏差の答えがすぐにパッと思いつく人はラッキーでしたね!
配点はそれぞれ1点ずつだったので,取りこぼした人もそんなにダメージは無いはずですが,,,
統計の世界では結構有名なので,データを扱う分野に進みたい人は覚えておこうね!
ちなみに,2019年のセンター試験,数学1Aの全ての問題の解答・解説はこちら
この記事はこんな人にオススメです 受験生の人 数学が好きな人 単純にセンター試験の問題が気になるひと こんにち…

実際のデータで標準化をみる
イメージがつきにくいかもしれないので,実際にデータを使って標準化をみてみましょう!

適当においらがパパッと作ってみました!
10人(Aさん〜Jさん)の1日の睡眠時間をデータ化したものです.
左の表にはそれぞれの睡眠時間と,標準化した値をプロットしています.
右のグラフは,それをプロットしたものになります.
青が加工なしの睡眠時間で,緑が標準化したデータになっています.
標準化は,10人のデータの平均値が0,標準偏差が1になるようにデータを加工することでした.
標準化された値を見ると,全体の値に比べて誰が一番寝不足で,誰が最も寝ているかというのが見やすくなりましたね!
標準化は平均値を0としているので,緑のデータがマイナスになれば,全体に比べて寝ていない人になりますし,プラスであれば寝ている人になります.
(あくまで,検討するデータの中の全体と比べてという話です)
一つのでデータで考察するときも効果的だけど,単位の概念が無くなるから違う計測を行ったデータとの比較もやりやすいんだよー!
このプラスマイナスをとる標準化されたデータは,睡眠時間という単位の概念がなくなります.
全体に比べてデータの値が大きいか小さいかのみが議論されます.
そのため,他のデータを持ってきた時(例えば,テストの点数とか)に比較して分析することが可能になるのです.
(例えば,よく寝た人は,テストの点数が高い傾向にあるとか,無いとか)
では!